
Event-Driven vs. Polling Architectures for Agent Triggers
The trigger layer is load-bearing infrastructure. Most agent teams treat it like a footnote.


Event-Driven vs. Polling Architectures for Agent Triggers
The demo works beautifully. An event fires, the agent responds, the workflow completes.
Then someone asks what happens when the webhook arrives late. Or out of order. Or twice. Or not at all. Silence.
This is a default problem, and I’ve watched it play out across enough teams to recognize the shape. Engineers reach for webhooks because they sound real-time, or for polling because it sounds simpler. Both defaults break under the reality of production SaaS. And agents are the first class of consumer where that breakage really hurts.
A dashboard that sees data five minutes late is annoying. An agent that sees data five minutes late can email the wrong customer, approve the wrong refund, or escalate a ticket that’s already been resolved. Trigger architecture isn’t a footnote in the system design doc. It’s load-bearing infrastructure.
Why Agent Triggers Break in Production
The agent systems I look at usually fall into two camps. Camp one picked webhooks because “real-time” and now deals with duplicate writes, out-of-order state updates, and silent gaps when the provider had a bad hour. Camp two picked polling because “simple” and now burns through rate limits while their agent runs minutes behind reality.
The deeper issue is that most teams frame the choice as a binary. Push or pull. Event-driven or polling. That framing leads to architectures that are brittle in exactly the ways agents can’t tolerate.
What I want to lay out here is different. Not two options, but four mechanisms, each with a distinct delivery contract. Not one right answer, but a decision framework based on what the source actually supports, what latency the workflow needs, and what happens when an event goes missing.
The Four Trigger Mechanisms and Their Delivery Contracts
The conversation gets stuck on two options because the language is imprecise. In practice, the trigger layer for agents has at least four distinct mechanisms.
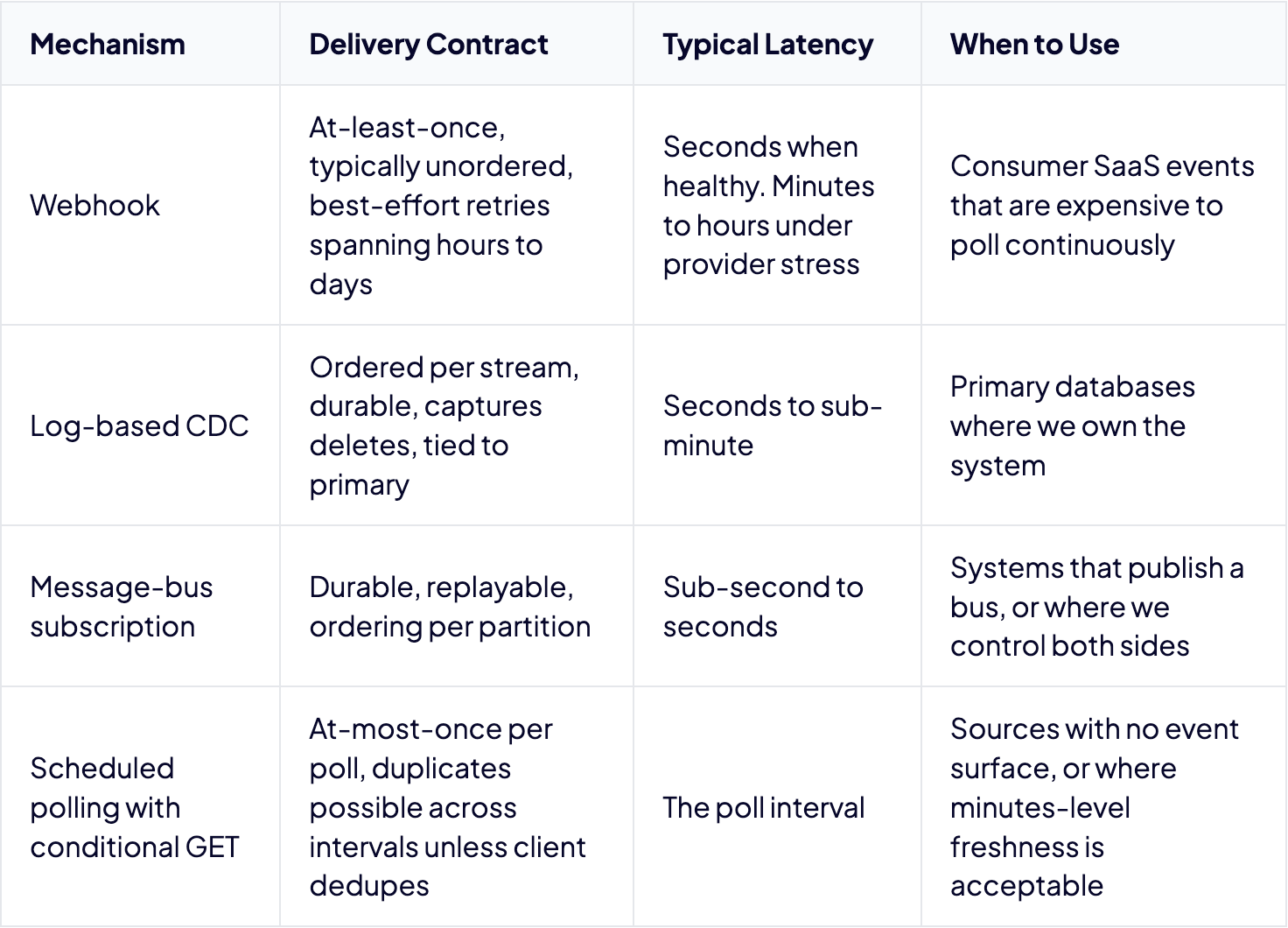
Webhooks are HTTP POST callbacks from SaaS providers. Delivery is at-least-once, unordered, and best-effort across most major providers. Source-side retention is measured in hours to days.
Log-based CDC reads a database transaction log through a tool like Debezium. Ordered per partition, durable, captures deletes. Tied to the primary database, not replicas, and requires operational investment.
Message-bus subscriptions connect to durable pub/sub systems like Kafka, Pulsar, AWS EventBridge, Salesforce Platform Events, or Google Pub/Sub. Replayable, support fan-out, ordering depends on partitioning.
Scheduled polling with conditional GET is client-initiated pull on a schedule. The universal fallback. Cost scales with interval and endpoint count, and it misses intermediate states between polls.
CDC and webhooks have very different ordering and durability properties. A message bus is not a webhook. Conditional polling is not the same animal as naive polling. Getting the design right starts with making the taxonomy precise.
“Real-Time” Webhooks Are Mostly Marketing
Across major SaaS webhook systems, the same caveats recur. Duplicates are possible. Order is often not guaranteed. Delivery under stress can be delayed.
Stripe attempts to deliver events for up to three days in live mode. Events may arrive out of order, and Stripe explicitly states that it doesn’t guarantee event delivery order. Every event carries a unique event.id for consumer-side deduplication.
Shopify doesn’t guarantee ordering within a topic, or across different topics for the same resource. A products/update webhook might arrive before the products/create webhook for the same product. Shopify retries up to 8 times over a 4-hour window, and retried webhooks carry the original payload from trigger time, not a freshly-fetched one. If the underlying data changed between the original delivery and the retry, the retry delivers stale data.
HubSpot’s Webhooks API retries up to 10 times over roughly 24 hours. Workflow-based webhooks have a different, longer retry schedule on the order of three days. The Webhooks API payload includes an attemptNumber field starting at 0, which signals that consumers should expect the same event more than once.
GitHub is the outlier. It documents handling for redelivery but does not present the same automatic retry model. Any agent trigger system using GitHub webhooks needs to either poll the deliveries API on a schedule and replay failed deliveries via the REST redeliver endpoint, or run a parallel polling sweep against the resources of interest.
Guaranteeing delivery order forces a choice between blocking the entire pipeline on a single failure or maintaining order only during success, which still forces consumers to handle out-of-order delivery in failure cases. Either way, the consumer needs out-of-order handling code.
A webhook tells me something changed. It does not tell me the truth about what changed, or in what order. An agent that trusts the order or uniqueness of webhook arrivals will write duplicate records, reason from stale state, or skip steps when events land in the wrong sequence.
Polling Hits a Ceiling Faster Than Teams Expect
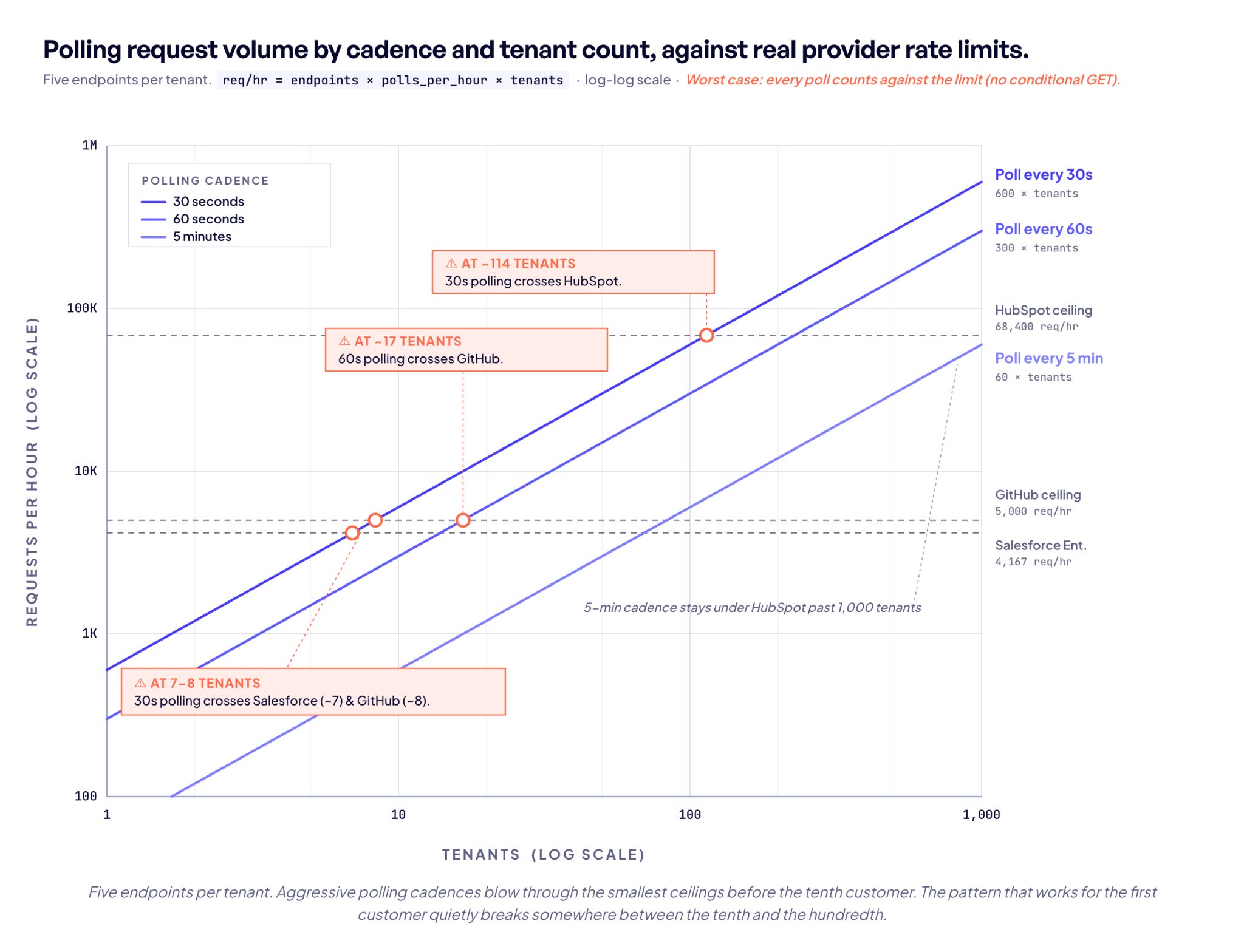
Polling feels cheap at first. One customer, a few endpoints, a 30-second interval. The math works. Then it doesn’t.
GitHub caps authenticated REST requests at 5,000 per hour. Polling 100 endpoints every 30 seconds generates 12,000 requests per hour. That’s 2.4x over budget before a single user action happens. Even 42 endpoints at that cadence consumes the entire hourly allocation, leaving zero headroom for anything else the application needs to do; user-triggered API calls, background syncs, retries on transient failures.
The standard mitigation is conditional GET with ETags or If-Modified-Since. On GitHub, a 304 response from an authenticated conditional GET does not count against the primary rate limit. That’s architecturally significant. But GitHub is the exception. HubSpot, Shopify, and Stripe don’t publish documentation confirming ETag or If-None-Match support, while Salesforce documents If-None-Match for some REST resources. Without conditional GET, every poll consumes quota regardless of whether the underlying data changed.
The scaling math gets worse with how rate limits are structured. HubSpot uses a per-app burst limit of 190 requests per 10 seconds on Professional plans for privately distributed apps, applied per app rather than shared across tenants. At 10 tenants, each one effectively gets 19 requests per 10 seconds. At 100 tenants, it’s 1.9. The per-tenant budget degrades linearly with scale.
Salesforce Enterprise starts at 100,000 requests per rolling 24-hour period per org. Running 10 tenants at 5 endpoints per tenant on a 30-second interval generates 144,000 requests per day. That’s 44% over the daily allocation. The pattern that works for the first customer quietly breaks somewhere between the tenth and the hundredth.
The Source Picks the Pattern
Teams spend days debating webhook versus polling as an abstract architecture question, when in practice the source system has already made much of the decision for them.
Many SaaS APIs either don’t support webhooks at all or only support them for a subset of objects. Odoo, Sage Accounting, and Pennylane don’t expose outgoing webhooks. Even Xero, which supports webhooks, uses a lightweight notification model where the webhook sends an events array and typically triggers a separate API fetch for the full resource data. Many APIs support webhooks only for certain objects, with inconsistent retry logic, ordering, and payload structure across providers.
Salesforce is the most instructive example. Rather than a single generic webhook object, it offers three overlapping event-driven mechanisms.
Outbound Messages are an older SOAP-based mechanism that retries failed deliveries for up to 24 hours rather than offering a replay window.
Platform Events are developer-defined custom messages. High-volume Platform Events offer a 72-hour replay window, while standard-volume events are retained for 24 hours. They can be published as part of a transaction, support multiple subscribers, and carry an EventUuid field for deduplication.
Change Data Capture automatically monitors enabled Salesforce objects with full coverage of UI, API, and bulk operations, delete tracking, and per-stream ordering via Replay IDs. Also a 72-hour replay window.
“Event-driven” is not one thing, even inside a single platform. CDC change events do not carry an EventUuid field the way Platform Events do. Identification relies on replay_id for stream position and ChangeEventHeader fields like transactionKey and sequenceNumber for transaction context. Replay IDs are monotonically increasing within a channel and unique within that channel’s retention window, but they are positional stream markers rather than globally unique identifiers. The real risk shows up at the boundaries: when Salesforce maintenance moves an org to a new instance, the retained event stream can be reset entirely, and the replay IDs that worked yesterday no longer point anywhere.
The right trigger architecture isn’t the one I prefer. It’s the best one the source will let me have. Teams building agents across dozens of sources aren’t making one choice. They’re making dozens, and each one is constrained by what the provider shipped.
Log-Based CDC Reads the Source of Truth
When we own the database, CDC changes the game. Instead of asking the application what happened, we read the transaction log directly. Every insert, update, and delete is captured, including intermediate states that polling would miss and that application-level webhooks might never emit.
Debezium on Postgres uses a logical replication slot to consume the Write-Ahead Log. The slot is durable and tracks where the consumer left off. Postgres requires wal_level = logical and the slot only works against the primary, not standby replicas. The default delivery guarantee is at-least-once. In failure and restart scenarios, the same event can be delivered twice. Debezium writes to Kafka with the row’s primary key as the message key, so per-row ordering is guaranteed within a partition. Cross-row ordering across partitions is not.
The biggest failure mode is WAL accumulation. When Debezium stops consuming, the replication slot holds WAL segments from recycling until disk is exhausted. Postgres offers max_slot_wal_keep_size as a circuit breaker, but if the slot exceeds that limit, it’s marked as lost and requires a full re-snapshot.
CDC is not a webhook. It reads from the source of truth, the log, not from application-level automation. For internal databases where we control the infrastructure, it’s the most precise trigger mechanism available. For SaaS sources where we don’t have database access, it’s off the table entirely.
The Fine Print on Message Buses
Kafka, Pulsar, EventBridge, and Pub/Sub all look similar from a distance. The details diverge in ways that matter for agent triggers.
Kafka producer defaults are at-least-once. Consumer semantics depend on commit configuration. With enable.auto.commit=true, offsets are committed on the next poll() call after the previous batch was returned, which in practice produces at-least-once delivery: a crash mid-processing means the next consumer replays the uncommitted batch on restart. The at-most-once case (commit landing before processing completes) is more characteristic of manual commit-before-process patterns than the auto-commit default. Either way, exactly-once is not the default. Exactly-once semantics are available via Kafka transactions, but the guarantee is scoped to Kafka-to-Kafka paths. The moment the agent makes an HTTP call or invokes an external API, that guarantee ends.
AWS EventBridge target retries are configurable, with a maximum event age tunable up to 24 hours and retry attempts between 0 and 185. Twenty-four hours is the ceiling, not a fixed value, and the default retention on the event bus itself is also 24 hours. EventBridge provides no ordering guarantee, and its archive replay re-matches events against current rules rather than the rules at original delivery, so a rule change between original delivery and replay can route a replayed event somewhere it never would have gone.
Google Pub/Sub’s opt-in exactly-once delivery holds only when the subscription is configured as single-region (not multi-region) and the subscriber uses the streaming pull API with acknowledgments returned inside the ack deadline. Agent fleets that pull from a multi-region subscription, or that miss the ack deadline under load, receive duplicates with no error signal that the guarantee was voided. Ordering is also opt-in and key-scoped, and redelivering one message cascades into re-delivery of all subsequent messages for that key, including already-acknowledged ones.
The common thread is that exactly-once delivery is typically unavailable by default, available only with significant constraints, or scoped to a narrower boundary than teams assume. The message bus adds durability and replay. It does not eliminate the need for idempotent handling.
Why Agents Change the Trigger Problem
Traditional trigger design assumes a short, deterministic handler. Receive event, process, done. Agents don’t fit that shape. An agent started from a trigger may wait on a human approval, block on an external API, call tools recursively, and need to survive across restarts. The trigger has to land in a system that can hold a durable state, not just an HTTP handler that returns 200.
In his piece on agent runtimes and durable execution, Vinoth Govindarajan captures the shape of the problem: ‘Useful agents often do work that crosses time. They wait for humans, tools, webhooks, timers, background jobs, and external systems. They fail halfway through. They retry. They resume. They create side effects that should not repeat by accident.’
Harrison Chase introduced the concept of ambient agents. ‘Ambient agents listen to an event stream and act on it accordingly, potentially acting on multiple events at a time.’
LangGraph’s trigger taxonomy maps to four categories. Event-driven, state-based, time-based, and external-input triggers, where the interrupt() function freezes execution at a checkpoint, persists the thread, and resumes when human input or a webhook callback arrives. No compute is consumed while the thread is paused.
The durable execution pattern is what makes long-running agents possible. Temporal implements it with workflows and signals, where each agent is a long-running workflow that maintains state and waits for Signals. Inngest uses memoized steps where step.run() caches results, so completed steps return cached results instantly on resume. Without durable execution, stateless retry patterns re-invoke LLM calls that had already completed successfully. That’s the token re-burning problem.
Picking a trigger mechanism without picking a matching runtime is where agent systems collapse. A webhook that fires a short-lived function that can’t survive a fifteen-minute LLM call, or an event that starts an agent with no idempotency key, looks fine in demos and fails in production.
Why Mature Systems Go Hybrid
My working assumption in mature systems is that events will be missed. Not might. Will.
Stripe documents the duplicate problem directly. “Webhook endpoints might occasionally receive the same event more than once. You can guard against duplicated event receipts by logging the event IDs you’ve processed.” For terminal payments, Stripe also notes that during outages reader action webhooks might be late and recommends querying the resource directly to know its latest state.
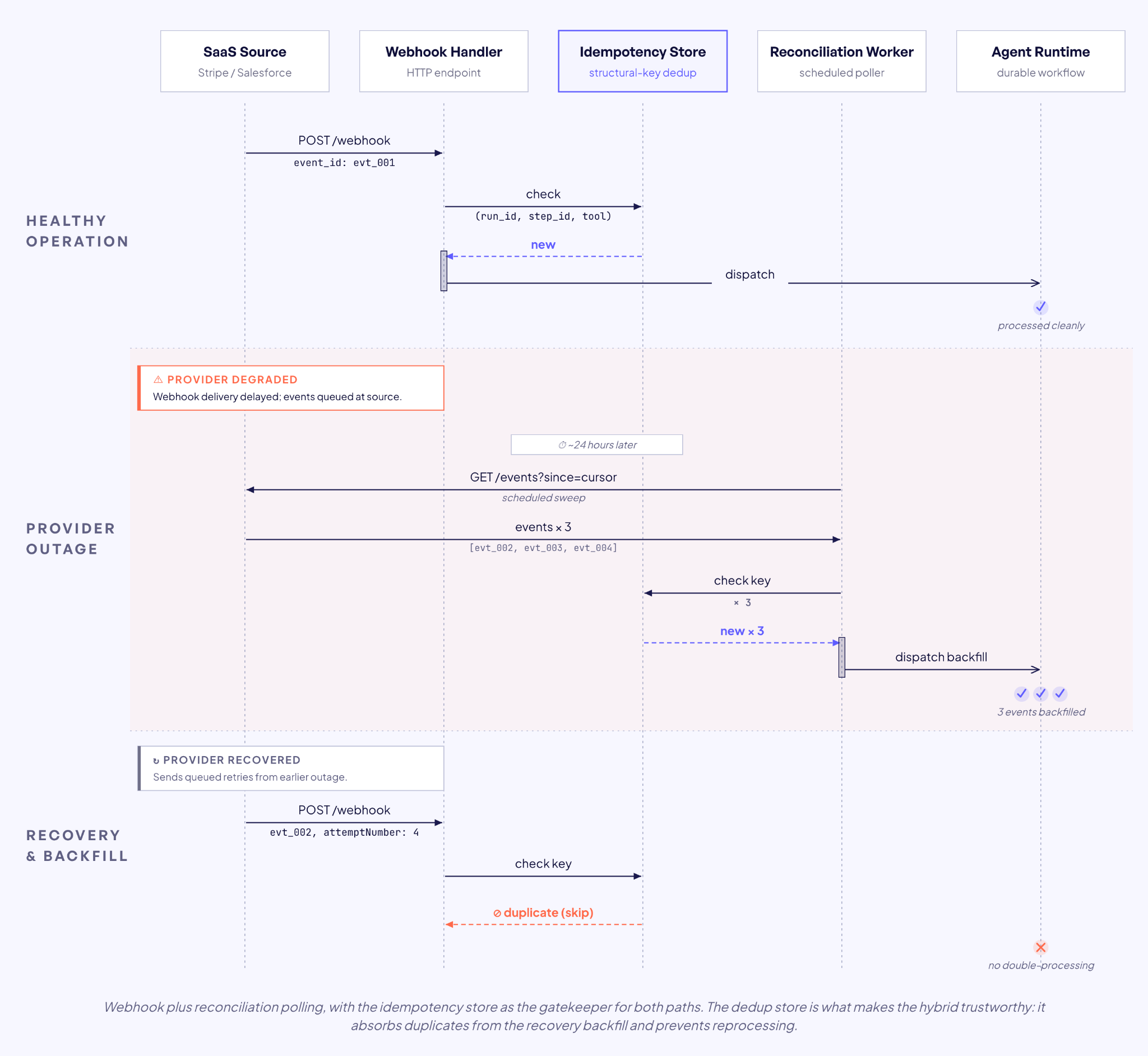
Merge’s guidance is webhook-plus-polling with a 24-hour safety-net poll at minimum, on top of more frequent polling tuned to the use case. Svix offers polling endpoints as a complementary delivery mechanism for when webhook delivery is unreliable. The shared logic is that consumers need a reconciliation process to keep the system honest.
The reconciliation job is what makes the hybrid trustworthy. It compares local state against source state and backfills gaps. The same idempotency check runs regardless of whether the event arrived via webhook or polling sweep.
The recovery procedure in practice is that the provider retry window exhausts, the circuit breaker opens, and the system switches to polling reconciliation. When normal webhook delivery resumes, the idempotency store prevents re-processing of events already caught during the polling sweep.
Teams that skip reconciliation ship agents that look correct until the first webhook outage, and then quietly emit wrong decisions for hours.
What the hybrid pattern doesn’t solve
The hybrid is not magic. It does not give exactly-once delivery on its own — that still depends on idempotent handlers. It does not catch events the source never emitted, like bugs in the provider’s own automation. It does not help with sources that have neither webhooks nor a reasonable polling surface, which is still common in legacy on-prem systems. And it doubles operational cost. Two delivery paths means two failure modes to monitor and two sets of metrics to understand.
If the source publishes a durable, replayable bus (Kafka, Pulsar, Salesforce’s Pub/Sub API), prefer that to webhooks plus polling. The bus gives reconciliation through replay, and you avoid maintaining a parallel poll loop. The hybrid is the right default when the source is HTTP-only. It isn’t the right default when something better exists.
Idempotency makes the hybrid honest
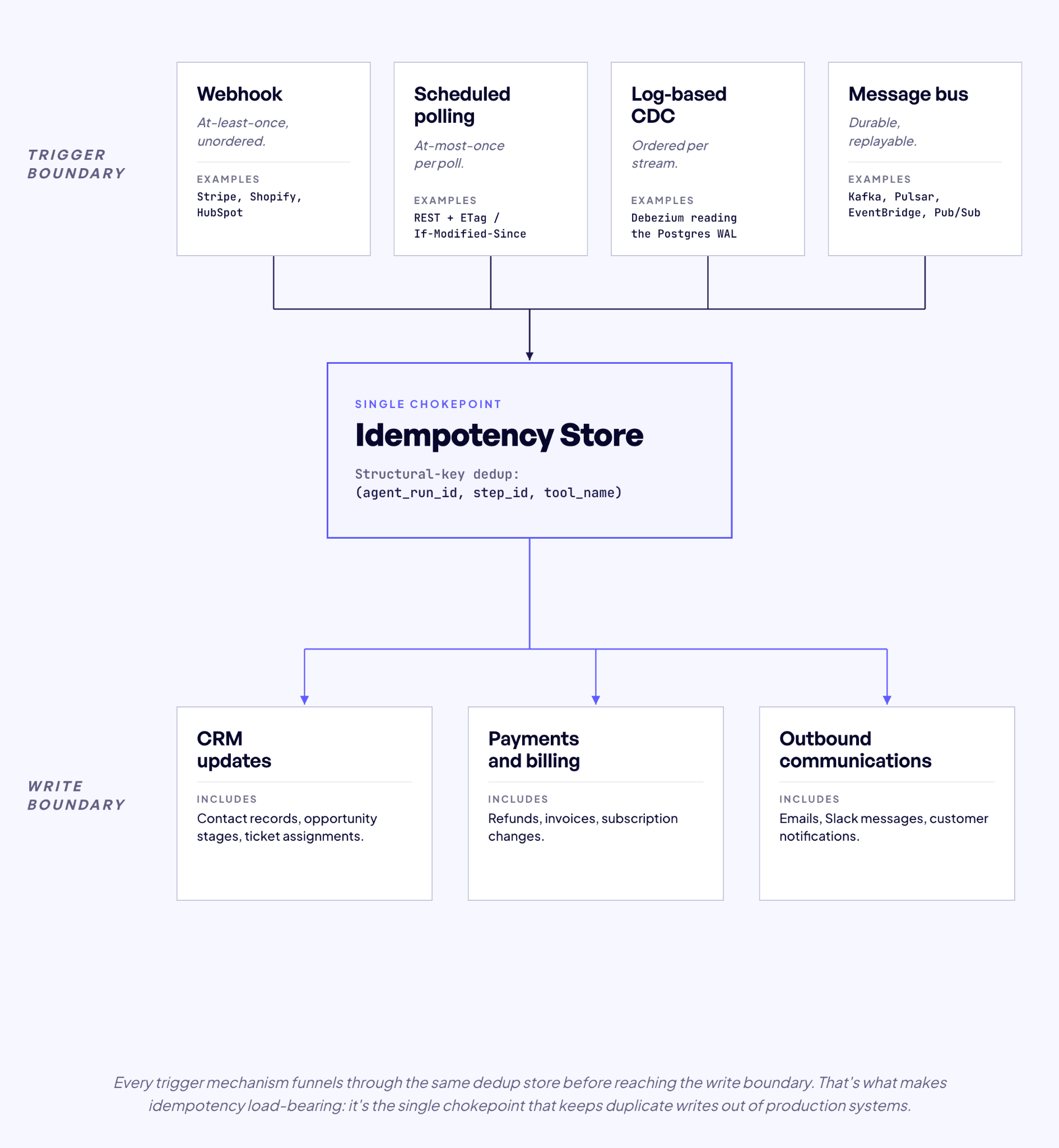
Duplicates are not an edge case. They’re implied by the delivery contract. Polling can duplicate across intervals. Webhooks can duplicate on retry. CDC can duplicate on replay. No trigger is exactly-once on its own. Exactly-once effects come from idempotent handlers at the write boundary.
Agents make idempotency harder because the writes that follow a trigger may be non-deterministic in content. The LLM is a non-deterministic client. If I hash tool parameters into the idempotency key, a retry that generates slightly different parameters produces a different key, and the destination treats the retry as a new write. I wrote about the idempotency key problem in detail in Designing Idempotent Write Operations for Business Agents.
The key must derive from stable structural context only. (agent_run_id, step_id, tool_name, call_index), optionally scoped by business identifiers. The call_index disambiguates the case where a single step invokes the same tool more than once — an agent loop creating several CRM contacts in one step, for example — so distinct intended writes don’t collide on the same key. All four components are assigned before LLM inference runs and do not change on retry.
def structural_key(
agent_run_id: str,
step_id: str,
tool_name: str,
call_index: int = 0,
) -> str:
“”“Derive the key from structural context only. Never from LLM output.”“”
raw = f”{agent_run_id}:{step_id}:{tool_name}:{call_index}”
return hashlib.sha256(raw.encode()).hexdigest()Picking an at-least-once trigger without a deduplication store at the write boundary is how payment duplicates, duplicate CRM contacts, and duplicate outbound emails get into production. Every one of those shows up as a model hallucination in the bug tracker when it was actually an infrastructure failure.
How to Choose the Right Trigger Architecture
Rather than webhook or poll, four questions get teams to the right architecture faster.
What latency does the workflow actually tolerate? Most workflows tolerate more than teams admit. An agent that processes support tickets doesn’t need sub-second triggers. An agent that responds to payment disputes might.
What does the source system actually offer? Webhooks, events, CDC, polling only. If the source doesn’t expose webhooks for the objects we care about, the architecture question resolves to polling.
What is the cost of a missed event versus a duplicate? If duplicates are cheap and misses are expensive, I want at-least-once plus reconciliation. If duplicates are catastrophic, I want stronger delivery semantics and idempotent handlers. In most agent systems I’ve seen, both are expensive. That’s why the hybrid pattern exists.
Where does the trigger land? The delivery mechanism has to match a runtime that can hold state for as long as the agent needs. A webhook that lands in a runtime with no memory of prior side effects is fragile by design.
Here’s how the mechanisms stack up.
I apply the framework per source. A multi-source agent system will use different mechanisms for different sources, and that isn’t a design flaw. It’s the correct response to heterogeneous source capabilities.
Do This Next
If I were starting the trigger layer for a new agent system on Monday, here’s the order.
Inventory delivery contracts before architecture. For every source the agent touches, write down whether it supports webhooks, the retry budget, the ordering guarantee, and the rate limit. Skip this and you’ll pick a pattern the source can’t support and discover it in production.
Build the idempotency store before the first integration. A structural-key dedup store at the write boundary makes every other choice survivable. Without it, the first duplicate webhook ships a duplicate write.
Default to webhook plus reconciliation, not webhook alone. Stand up the polling backstop on day one, even if the webhook works perfectly in staging. The first webhook outage is the wrong time to design the recovery path.
Pick a runtime that can hold state across waits. If your trigger lands in a stateless function, the next fifteen-minute LLM call kills the run. Durable workflow runtimes solve this. Plain HTTP handlers don’t.
Treat trigger choice as per-source, not per-system. A multi-source agent will use different mechanisms for different sources. That’s correct. Pretending one pattern fits everything is how trigger layers age into rewrites.
Skip the first and you ship architectures the source can’t support. Skip the second and you ship duplicate writes. Skip the third and you go quiet during outages. Skip the fourth and your runs die mid-decision. Skip the fifth and you write the same retry logic five different ways.
What It All Comes Down To
There is no universal right answer to webhook or poll. In production, the right pattern is usually a combination of fast-path events, reconciliation polling, idempotent handlers at the write boundary, and a durable runtime that can hold state across the gaps.
When I’m designing the trigger layer for a new agent system, I run the same four questions per source. Latency tolerance. What the source actually offers. The cost of a miss versus a duplicate. Where the trigger lands. The answers usually produce a different architecture for every source. That is the point.
The trigger and the write are two halves of the same problem. Both have to be designed for at-least-once reality from the first day. I covered the write boundary in Designing Idempotent Write Operations for Business Agents. This piece covers the trigger boundary. Together they bracket the most common failure modes I see in production agent systems.
Trigger architecture is the under-invested layer in most agent stacks I look at. It deserves the same rigor as model selection, retrieval, and prompt design. Not as a footnote. As a foundation.