
Designing Idempotent Write Operations for Business Agents
The problem: idempotency is a property of the destination, not a property you can impose from the caller.


Every week I talk to teams building agents that can read from CRMs, query databases, and summarize documents. The demos look great until you ask a simple question.
Can it also write back?
Reading is the easy part. Writing is where agent systems start looking like infrastructure. The hard part is that the client doing the writing is an LLM, and the destination receiving the write was not designed for a non-deterministic client.
Most teams start this work looking for idempotency. They assume they can make writes safe by generating the right key and sending it in a header. That works when the destination supports it. A lot of destinations do not. Stripe supports idempotency keys. Salesforce supports external IDs for upsert, which gets you part of the way. Jira, Gmail, Slack, most HRIS systems, and a long tail of internal APIs do not expose idempotency primitives at all.
This is the part of the problem people skip past. Idempotency is a property of the destination, not a property you can impose from the caller. If the destination does not support it, no key on your side will fix the duplicate record in Salesforce, the second email in the inbox, or the reposted Slack message.
So most of the engineering work is not building idempotency. It is building safety around it. The patterns that matter are the ones that keep you safe when the destination will not cooperate, when the caller retries at the wrong moment, and when nobody can tell from the response whether the write actually landed. That has always been hard in distributed systems. Agents make it harder, because the caller is now non-deterministic in ways that classical retry frameworks never had to handle.
Why Agents Make an Already-Hard Problem Worse
This problem is not new. Integration engineers have been dealing with unreliable destinations, mid-flight failures, and ambiguous server responses for as long as there have been distributed systems. The standard defenses are well understood: idempotent endpoints where you can get them, read-back verification where you cannot, deduplication stores in front of fragile destinations, outbox tables to decouple the caller from the retry loop. None of this was invented for agents.
What agents change is the caller. Traditional retry logic assumes a deterministic caller. A service crashes, a job queue replays the same request with the same payload, and the destination either accepts it again or rejects the duplicate. The request did not change between attempts. That assumption is load-bearing. When it holds, a lot of the classical defenses become simple. When it does not, every defense has to account for a caller that may behave differently each time it runs.
LLMs break that assumption in three ways, and each one weakens a different defense.
Deciding whether to write at all. Even at temperature=0, LLMs are not deterministic. Thinking Machines Lab showed that 1,000 runs of the same prompt under dynamic batching produced roughly 80 unique completions. A study from Penn State measured up to a 70% best-to-worst performance gap at temperature=0 with a fixed seed. Replay the same step and the agent may choose to act, skip the action, or call a different tool. Classical retry defenses assume the retry is a retry. With agents, it may be a different decision entirely.
Deciding what to write. Even when the agent consistently decides to act, the payload may differ on retry. Different email body, different CRM field values, different ticket title. This breaks any defense that leans on payload equivalence. Hash-based dedup fails silently. Naive compensation assumes the thing you are compensating for is the thing you think was written.
Phantom success problem. In their analysis of 14,000 sandboxed agent sessions, a startup reported roughly 12% of sessions with error states produced a final message that did not reflect what happened. Microsoft’s engineering team documented the same pattern: “Agents will never tell you they failed. They’ll report success with elaborate detail.” This breaks the status-code defense. If the agent believes the write succeeded when it did not, compensation logic never triggers.
A lot of production failures get mislabeled as model failures when they are really failures in the infrastructure around the model. The defenses have to be rebuilt with the assumption that the caller is non-deterministic, the payload is non-deterministic, and the caller’s self-report is non-deterministic.
The evidence is piling up. LangGraph had a reported bug where a human approval flow produced multiple tool results for a single tool call. A separate open issue documents entire ToolNodes re-executing when a SubAgent resumes from an interrupt. OpenAI’s Agents SDK includes retry logic for model requests but provides no idempotency-key infrastructure or write-side deduplication for tool calls. CrewAI practitioners report agents getting stuck in forever-loop execution. As of early 2026, no official docs across LangGraph, PydanticAI, CrewAI, Google ADK, OpenAI Agents SDK, or Microsoft AutoGen describe built-in idempotency key management or deduplication stores for tool calls that write to external systems. The defenses exist in the distributed-systems literature. They have not been ported into agent frameworks.
What Does a Write-Safety Strategy Actually Look Like?
A write-safety strategy is a layered set of controls around the write boundary. You start with whatever the destination gives you, then build caller-side safety to handle everything it does not. No single layer is sufficient on its own.
The strategy has four layers, applied in this order.

Use Native Idempotency When the Destination Supports It
The cheapest and most reliable layer is the one you did not have to build. Check the destination first. Stripe supports an Idempotency-Key header as a V4 UUID or random string with sufficient entropy. Salesforce supports external IDs for upsert operations, which deduplicates creates on your chosen business key. Some modern SaaS APIs expose dedup headers or conditional writes. When these exist, use them.
One engineering principle matters more than the rest. Never derive the idempotency key from LLM output. The LLM is a non-deterministic client. If you hash tool parameters into the key, a retry that generates slightly different parameters produces a different key, and the destination treats the retry as a new write. The key must come from stable structural context only. Something like (agent_run_id, step_id, tool_name), optionally scoped by a stable business identifier. When the same structural key arrives with different parameters, Stripe’s parameter mismatch detection pattern applies: flag the mismatch rather than silently executing a second write.
This layer covers a minority of production writes. Everything else goes to destinations that will not help you.
Read Back to Verify What Actually Happened
For destinations that do not support idempotency, the most effective control is the simplest one. After a write, read back. Query the destination for the record you just created or updated. Confirm it exists and matches your intent. If the write failed silently, or timed out after the server committed it, or succeeded then rolled back, the read-back tells you the truth. The response to the write call does not.
This pattern predates agents by decades. It is how cautious integration engineers have always handled unreliable destinations. The question is: how do you enforce it when the caller is an LLM?
The wrong answer is to ask the agent to read back. The LLM may skip the step, misinterpret the result, hallucinate a record that does not exist, or return a confident success report that does not match the destination state. The phantom-success pattern documented earlier is this exact failure. Verification has to live outside the model.
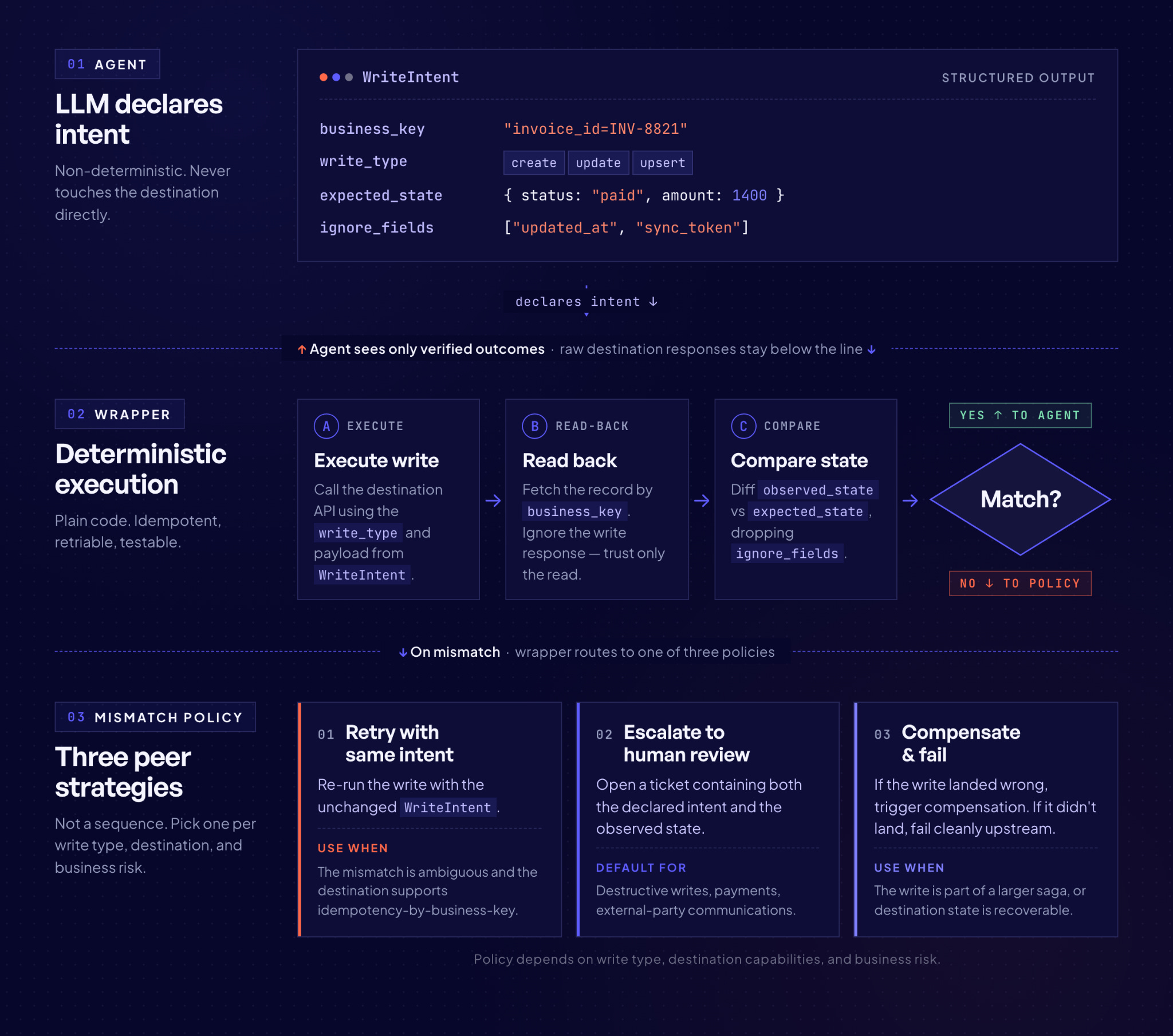
The pattern that works is a write-intent contract. The agent does not call the destination directly. It calls a deterministic wrapper, and to call the wrapper it must declare, in a structured form that the wrapper can verify, what the write is supposed to accomplish. The wrapper executes the write, reads back, compares the read result to the declared intent using deterministic rules, and returns a verified outcome. The LLM never sees the raw destination response. It only sees whether verification passed.
Concretely, the contract needs four fields for every write:
A stable business key that identifies the record in the destination (email address for a CRM contact, external ID for a Salesforce object, thread ID for a Slack message). The agent must supply this before the write, not infer it from the response.
A write type: create, update, or upsert. Each one has different verification rules.
An expected state: the field values that must be present on the record after the write succeeds. This is the agent’s declared intent, locked in before the call.
A tolerance policy for fields the agent does not care about. Destinations often add timestamps, system IDs, or normalized values that differ from what was submitted. The wrapper needs to know which differences count.
from dataclasses import dataclass
from typing import Literal, Any
@dataclass
class WriteIntent:
business_key: dict[str, Any] # e.g. {”email”: “a@b.com”}
write_type: Literal[”create”, “update”, “upsert”]
expected_state: dict[str, Any] # fields that MUST match on read-back
ignore_fields: list[str] # fields the destination may mutate
def execute_with_readback(intent: WriteIntent, execute_fn, read_fn):
write_result = execute_fn() # perform the write
observed = read_fn(intent.business_key) # read back by business key
if observed is None:
if intent.write_type in (”create”, “upsert”):
raise WriteVerificationFailed(”record not found after write”)
# For update, a missing record is a different kind of failure
raise WriteVerificationFailed(”target record missing”)
mismatches = {
k: (intent.expected_state[k], observed.get(k))
for k in intent.expected_state
if k not in intent.ignore_fields
and observed.get(k) != intent.expected_state[k]
}
if mismatches:
raise WriteVerificationFailed(mismatches=mismatches)
return observedA few things worth calling out. The agent’s job ends when it produces the WriteIntent. Execution and verification are code. The business_key has to be something the destination can be queried by, meaning a deterministic lookup rather than a full-text search, because a full-text search on the LLM’s paraphrase of the record is a second point where non-determinism creeps in.
This works cleanly for upsert and update flows, where the business key is known before the call. Pure create flows where the destination assigns the primary ID are harder. The pattern that works there is to have the agent generate a stable client-side ID (a UUID derived from structural context, never from LLM output) and write it into a custom “external ID” field on the destination record. The read-back then queries by that field. If the destination has no custom-field surface at all, creates fall back to the outbox layer for at-most-once delivery semantics.
On mismatch, the wrapper raises rather than returning a soft success, which prevents the phantom-success pattern from hiding a failure. What the wrapper does with a mismatch is a design decision that depends on the write type and the destination.
Three reasonable policies:
Retry with the same intent. Safe when the mismatch is ambiguous and the destination supports idempotency-by-business-key. Unsafe otherwise, because you may be re-writing over a concurrent update.
Escalate to human review. The correct default for destructive writes, payments, and anything sent to external parties. The mismatch becomes a ticket with both the declared intent and the observed state attached.
Compensate and fail. If the write landed but produced the wrong state, run the compensation path. If the write did not land at all, fail cleanly and let upstream logic decide whether to retry.
Three limits worth being honest about.
Read-back is not free. It doubles the number of API calls and adds latency, and on rate-limited destinations it can become the bottleneck. A sampling strategy, where high-value writes are verified synchronously and lower-value writes are reconciled in a batch job, is often the right compromise.
Read-back cannot see a write that arrived, was persisted, and was then rolled back by the destination between the write response and the read-back query. For that narrow window, the defense is the outbox layer below, which replays from persisted intent rather than from the model.
Many SaaS destinations do not guarantee read-your-writes consistency. Salesforce, Jira, and most API gateways route reads to replicas that can lag the primary by seconds. An immediate read-back can legitimately return stale data or a “not found” for a record that was in fact written. The fix is to retry the read with short backoff before declaring verification failed, and to treat a persistent miss as a real failure rather than a transient one. Without this, read-back verification produces false negatives that look exactly like the failure cases it was built to catch.
Caller-Side Deduplication to Catch the Retry Before It Leaves
Native idempotency and read-back both happen after the request is in flight. Caller-side deduplication catches the duplicate before it leaves your system. This is the layer that handles the scenario where your agent crashes mid-workflow, the framework resumes from a checkpoint, and the tool call fires a second time against a destination that would happily accept both.
The mechanism is a deduplication store keyed by structural context. Before the tool call executes, the wrapper checks whether that structural key has already been processed. If it has, the wrapper returns the cached result instead of re-calling the destination.
CREATE TABLE write_dedup (
key TEXT PRIMARY KEY,
params_hash TEXT NOT NULL,
status TEXT NOT NULL, -- ‘done’ | ‘failed’
result JSONB,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);import hashlib, json, logging
def structural_key(agent_run_id: str, step_id: str, tool_name: str) -> str:
“”“Derive the key from structural context only. Never from LLM output.”“”
raw = f”{agent_run_id}:{step_id}:{tool_name}”
return hashlib.sha256(raw.encode()).hexdigest()
def execute_with_dedup(agent_run_id, step_id, tool_name, params, db, execute_fn):
key = structural_key(agent_run_id, step_id, tool_name)
params_hash = hashlib.sha256(
json.dumps(params, sort_keys=True).encode()
).hexdigest()
# Fast path: has this key already completed? No locks, just a read.
existing = db.query_one(
“SELECT params_hash, status, result FROM write_dedup WHERE key = %s”,
[key],
)
if existing and existing.status == “done”:
if existing.params_hash != params_hash:
logging.error(
“Parameter mismatch on key=%s | original=%s | retry=%s”,
key, existing.params_hash, params_hash,
)
raise ParameterMismatchError(key=key)
return existing.result
# Not seen before. Execute, then record atomically with ON CONFLICT
# as a safety net for the rare concurrent-worker race.
result = execute_fn(params)
db.execute(
“”“
INSERT INTO write_dedup (key, params_hash, status, result)
VALUES (%s, %s, ‘done’, %s)
ON CONFLICT (key) DO NOTHING
“”“,
[key, params_hash, json.dumps(result)],
)
return resultTwo details matter here. The check-then-execute flow never holds a database row lock across the external API call, so batches of 50 requests at 500ms each do not serialize behind a 25-second lock. The INSERT ... ON CONFLICT DO NOTHING is the safety net for the narrow window where two workers happen to pick up the same structural key in parallel. The first one to commit wins, the second one silently drops its record, and the next retry reads back the committed result.
This layer has two failure modes worth naming. First, if the worker crashes after executing the destination call but before inserting the dedup record, the retry will execute the call a second time. Second, if two workers pick up the same structural key in parallel, both will pass the initial SELECT before either inserts, and both will execute the destination call. ON CONFLICT DO NOTHING prevents the duplicate row, not the duplicate write.
The first case is rare and bounded to worker restarts. The second is bounded to checkpoint replay and framework bugs that fan out the same step across workers, but it occurs.
For destinations with native idempotency or effective read-back, both cases are recoverable. For destinations that support neither, this is where the next layer earns its keep.
Move the Retry Loop Out of the Agent Entirely
The most effective change is to stop asking the LLM to be part of the retry loop. The transactional outbox pattern records the write intent in an outbox table within the same database transaction as the agent’s state update. From that point forward, a deterministic background worker reads the outbox and handles delivery. The LLM is done. Retries replay persisted state, not model decisions.

CREATE TABLE write_outbox (
id BIGSERIAL PRIMARY KEY,
idempotency_key TEXT UNIQUE NOT NULL,
agent_run_id TEXT NOT NULL,
step_id TEXT NOT NULL,
tool_name TEXT NOT NULL,
payload JSONB NOT NULL,
status TEXT NOT NULL DEFAULT 'pending', -- pending → processing → delivered | failed
attempts INT NOT NULL DEFAULT 0,
last_error TEXT,
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
delivered_at TIMESTAMPTZ
);
CREATE INDEX idx_outbox_pending ON write_outbox (id) WHERE status = 'pending';def process_outbox(db, http_client, max_attempts=5, batch_size=50):
# Phase 1 - Claim: short transaction, locks held only milliseconds.
with db.transaction():
rows = db.query(
"""
SELECT id, idempotency_key, tool_name, payload, attempts
FROM write_outbox
WHERE status = 'pending' AND attempts < %s
ORDER BY id ASC
FOR UPDATE SKIP LOCKED
LIMIT %s
""",
[max_attempts, batch_size],
)
if not rows:
return
db.execute(
"UPDATE write_outbox SET status = 'processing' WHERE id = ANY(%s)",
[[row.id for row in rows]],
)
# Transaction commits here. Locks released. Other workers unblocked.
# Phase 2 - Deliver: no transaction, no locks held during HTTP calls.
for row in rows:
try:
http_client.post(
endpoint_for(row.tool_name),
json=row.payload,
headers={"Idempotency-Key": row.idempotency_key},
)
db.execute(
"UPDATE write_outbox SET status = 'delivered', delivered_at = now() WHERE id = %s",
[row.id],
)
except Exception as e:
db.execute(
"""
UPDATE write_outbox SET status = 'pending',
attempts = attempts + 1, last_error = %s
WHERE id = %s
""",
[str(e), row.id],
)The outbox does not eliminate at-least-once delivery. The destination may still receive the same call twice if the worker crashes between the HTTP response and the status update. Airbnb learned the hard way that even the outbox pattern requires reading idempotency state from the master database, not replicas. The outbox is powerful, but it is part of the strategy, not a substitute for it.
How Do You Coordinate Writes Across Multiple Systems?
Many business agents do not do one write. They create a Salesforce contact, create a Jira ticket, and send an email. Three systems, three different rollback semantics, and no shared transaction boundary.
The saga pattern is the standard answer: a sequence of local transactions where each step has a defined compensating transaction, executed in reverse order if a later step fails. AWS has published official prescriptive guidance applying this pattern to agentic AI directly.
Every write classifies along what Chris Richardson calls an irreversibility spectrum: compensable, pivot (the point of no return), and retryable. Gregor Hohpe’s complementary guidance is to perform the hardest-to-revert action last. Once an email has been sent, it generally cannot be reversed. The only mitigations are delayed execution, human confirmation gates, or semantic compensation.
Temporal’s guidance on saga implementation is clear: register the compensation before executing the activity, not after. Without that discipline, multi-step workflows turn into partial failures that nobody can safely recover from.
So What Does This Mean for You?
Different roles carry different parts of this problem. Here is where the work lands.
If you build agent frameworks or infrastructure: Idempotency wrappers, read-back helpers, deduplication stores, and outbox primitives should be first-class abstractions. Today, none of the major frameworks ship these. That gap is yours to close. Provide structural key generation, parameter mismatch detection, durable write-intent storage, and destination capability probes out of the box.
If you wire agents to CRMs, payment systems, or other external services: Do not assume the framework handles write safety. Start by cataloging what each destination actually supports. Own the key strategy for every tool that mutates state, classify each write along the reversibility spectrum, and design compensating actions before you go to production. Test what happens when your agent crashes mid-workflow and replays. If you have not tested the retry path, you do not have a production system.
If you are an engineering leader or platform owner: Write safety is a platform concern, not a per-team concern. Set organization-wide standards for risk classification (AUTO / LOG / REQUIRE_APPROVAL), mandate structured decision traces with correlation IDs, and invest in runtime supervision infrastructure (kill switches, rate limiting, circuit breakers) as shared services. The cost of one duplicate payment or one unsanctioned email at scale will exceed the cost of building this layer correctly.
Do This Next
Pick the first item you have not done and work down the list. Each step builds on the one before it.
Catalog what each destination supports. For every API your agents write to, record whether it has native idempotency, upsert by external ID, conditional writes, or nothing. Your strategy cannot be uniform if the destinations are not.
Use native idempotency everywhere it exists. Derive keys from stable structural context only, never from LLM output. Never hash tool parameters into the key. Use parameter mismatch detection to catch non-determinism before it reaches downstream systems.
Add read-back verification for destinations without idempotency. After writing, read the record you just touched, verify it matches intent, and surface any mismatch as a failure rather than a success. Sample lower-value writes if full read-back is too expensive.
Move write retries behind a transactional outbox. Record the write intent in an outbox table within the same database transaction as the agent’s state update. A deterministic background processor executes the external call and retries from persisted state, not from the LLM. This removes the model from the retry loop entirely.
Classify every write by risk and wire that classification into execution. Tag each tool as
AUTO,LOG, orREQUIRE_APPROVAL. Enforce at the infrastructure layer, not in the prompt.Emit a structured decision trace for every write, with a correlation ID that propagates through every sub-agent, tool call, and API request. Cover input context, exact tool parameters, expected vs. actual outcome, and policy evaluation result. OpenTelemetry’s GenAI semantic conventions define the span shape; Langfuse and LangSmith provide the instrumentation layer. If you cannot reconstruct what happened from the trace alone, the trace is not complete. Teams that build this early find problems in staging. Teams that skip it find them in customer-facing incidents.
The Strategy That Emerges
Write safety for agents is not a single pattern. It is a layered strategy that starts with what the destination supports, fills the gaps with read-back verification, adds caller-side deduplication to catch retries in your own process, and moves the retry loop out of the LLM entirely with a transactional outbox. Saga orchestration sits on top for multi-system flows. Risk classification and structured traces make the whole thing operable.
Data access gets the attention because it helps the model see. Write infrastructure decides whether the system is safe. The strategy sits right in the middle of governance, orchestration, and observability, and most of it is scaffolding around destinations that were never designed for a non-deterministic client.