
The Missing Context Layer
Why your LLM agent can’t do more than Text-to-SQL


The Missing Context Layer
The semantic layer was one of the most important abstractions the modern data stack produced. It externalized business logic, made metrics consistent across tools, and gave analysts a shared language for what “revenue” and “churn” mean.
Every semantic layer tool, whether it’s MetricFlow, LookML, or Cube, answers the same fundamental question. What does this metric mean, and how do I calculate it consistently?
That’s the right question when your consumer is a human analyst looking at a dashboard. It’s the wrong question when your consumer is an agent trying to figure out that a Stripe charge, a Zendesk ticket, and a Salesforce contact all belong to the same person, and that this person just had a terrible experience.
The semantic layer solved the metric problem. It was never designed to solve the entity problem. And agents need entities.
Agents Break Even With a Semantic Layer
Every week I talk to founders and operators building agents on top of mature data stacks. These are teams with dbt, LookML, Cube, governed metric definitions, and dashboards that agree with each other. They did the hard work.
And their agents still break.
What Actually Breaks in Production?
The models are fine and the prompts aren’t the issue. The common failure mode I keep seeing is simpler. The agent can’t reliably resolve that records across billing, support, and CRM refer to the same real-world customer.
Semantic layers were built for analysts asking aggregate questions in BI. Agents need to resolve entities, follow relationships, and take actions across systems. That’s a different workload entirely, and no amount of metric governance was designed to support it.
Why Metric Abstractions Don’t Provide Navigation
An agent resolving a customer issue has to navigate. It starts with a customer, follows relationships to transactions, then follows more relationships to refunds, tickets, and emails before deciding on an action and executing it.
That workflow breaks because nobody built the entity and relationship map the agent needs to traverse. MRR definitions don’t enter into it. The agent has nowhere to look up how objects in different systems relate to each other, so every cross-system step becomes a guess.
This gap shows up in what I think of as the 8 Layers of Context Engineering. Semantic layers address one of those layers, meaning, by making metrics consistent. But agents also need structure (entities and relationships across systems) and control (permissions, allowed actions, auditability). Most teams invest heavily in meaning and discover the other two are missing only after the first impressive demo hits operational edge cases.
What Agents Need Around the Semantic Layer
The capabilities that determine whether agent workflows survive production sit around the semantic layer, not inside it.
Identity: How records across systems collapse into the same entity
Relationships: How entities connect, so an agent can traverse from one to another
Actions: What the agent is allowed to do, and how writes are validated and audited
When teams tell me “we have a semantic layer, why can’t the agent do this,” they’ve usually solved metric meaning and assumed the rest would follow. It doesn’t. Metric meaning gives the agent a vocabulary. Structure and control give it the ability to navigate across systems and take actions safely. Without all three, the agent is articulate but lost.
The Wrong Unit of Abstraction
The problem runs deeper than a missing feature. It’s a mismatch in the unit of abstraction the entire modern data stack was built around.
For the past decade, “understanding your data” meant defining metrics. What counts as revenue. How churn is calculated. What makes a user active. The entire toolchain optimized for it. dbt models, LookML explores, Cube dimensions, Tableau calculated fields. The metric became the atomic unit of data infrastructure.
This was the right work, but it created a blind spot that’s now shaping how agents fail.
The Entity Gap Semantic Layers Don’t Close
In a lot of teams I talk to, people can tell you exactly what MRR means and be confident it’s consistent across every dashboard. They often cannot tell you that customer_id 4821 in Stripe is the same person as jsmith@acme.com in Zendesk. The industry solved consistency of meaning for aggregates without ever operationalizing consistency of identity across systems, and that asymmetry is now the bottleneck.
The BI era made the metric the first-class citizen of data infrastructure. The agentic era requires making the entity the first-class citizen. This is a paradigm shift, not a feature gap. Almost every tool in the modern data stack exists to define, govern, and query metrics. Far fewer tools, workflows, and roles exist to resolve, connect, and traverse entities across systems. Right now, almost nobody is building them.
That imbalance explains why so many teams with excellent data governance still can’t get an agent through a multi-step workflow. As Jessica Talisman observed in Metadata Weekly, the entire modern data stack was built on the assumption that measurement is the foundation of understanding, but AI systems reason differently than human analysts. They don’t need metrics presented in charts. They need concepts, relationships, and the ability to infer.
What the Text-to-SQL Graveyard Predicts
After ChatGPT launched, a wave of teams built text-to-SQL products. Chat with your database, get instant answers. A pattern I heard repeatedly from builders in that wave is that sustained production usage was hard to achieve outside of narrow, clean setups.
The standard post-mortem blames simplistic implementations or model quality. In the conversations I’ve had, the failure mode looked different.
Why It Looks Great in a Single System & Falls Apart Across Systems
Text-to-SQL works surprisingly well when the question lives inside one system with a clean schema. “How many orders last week.” “Top SKUs.” “Revenue by day.” The schema contains everything the model needs, so the model looks brilliant.
Then teams add a second and third system. Support tickets. Refunds. Billing events. CRM contacts. Suddenly the agent isn’t failing on SQL generation. It’s failing on meaning that isn’t in the schema: which ticket belongs to which order, which refund belongs to which customer, or what makes a support experience “negative” in this company. The model can’t reason about relationships that nobody defined.
Those teams failed because they inherited the semantic layer’s assumption that “understanding data” means knowing what columns mean. They discovered that agents need something the column-level abstraction can’t provide, which is knowledge of how entities connect across systems. The single-system success actually made the multi-system failure harder to diagnose, because the team had evidence that “it works.”
This is a structural prediction, not just a cautionary tale about a cohort of startups. Every team building agents on top of their semantic layer without an ontology is running the same experiment with a longer fuse.
Dictionary vs. Map
A semantic layer is a dictionary. It defines what words mean. An ontology is a map. It defines how things connect. You can have a perfect dictionary and still be lost.
Semantic Layer vs. Ontology

As Kirk Marple puts it: the metadata is the model. Providing agents with a semantic ontology is just as important as the data itself. When ontology gets populated with live data, it becomes a knowledge graph. Think of it as a living, operational network of entities and relationships that agents can traverse in real time. The semantic layer never needed to become this because dashboards don’t traverse. Agents do.
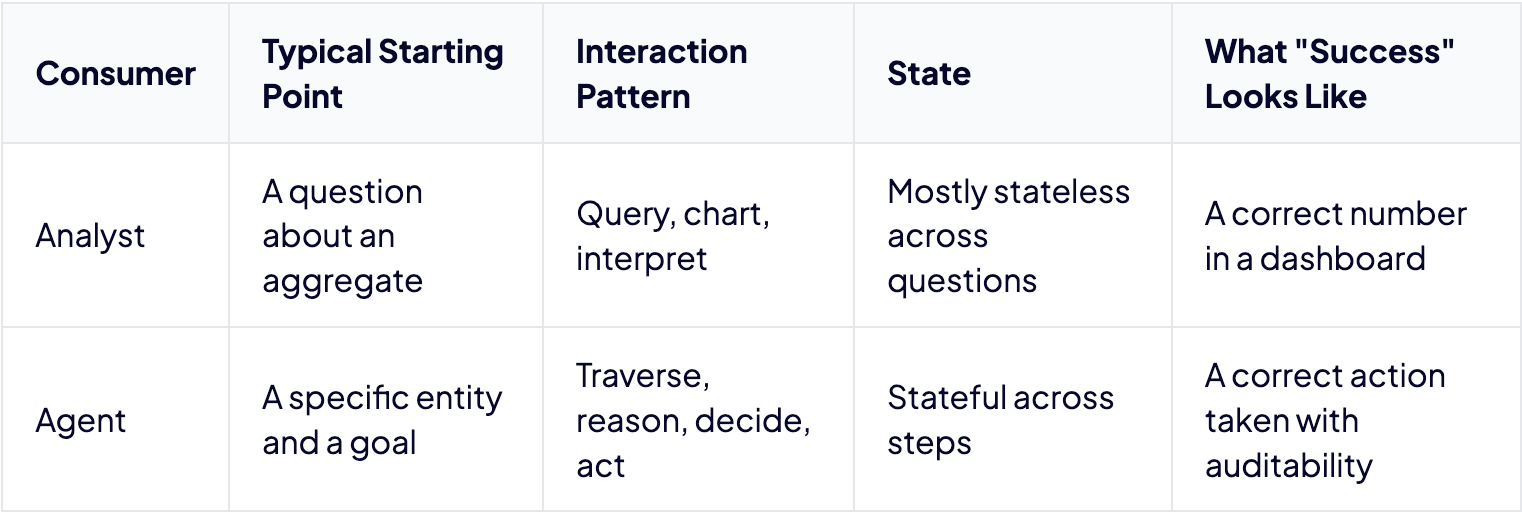
Analyst Workflow vs. Agent Workflow
The distinction becomes visceral when you compare how analysts and agents actually operate.
An analyst asks a question and gets a number. An agent starts with a customer, follows a relationship to their recent transactions, follows another to refund activity, follows another to open support tickets, checks communication history, decides on an action, and executes a write. Each step depends on the prior step. Each step requires understanding a connection between one entity and another. That’s traversal, and traversal requires a map, not a dictionary.
The Convergence Trap
The industry sees the problem and the instinct is predictable. Extend what already exists.
dbt open-sourced MetricFlow and framed it as the bridge between AI and structured data. Microsoft introduced an ontology-based IQ layer at Ignite, a move notable enough that SoftwareReviews observed it was the first time Microsoft had used the term “ontology” in this context.
Galaxy, Atlan, and other semantic layer vendors have started bolting entity resolution and relationship modeling alongside metric governance. The story the industry tells is convergence, the semantic layer evolving to meet the agentic era.
That framing is a trap.
Why Metric-First Extensions Fight the Architecture
When a metric-first system gets entity awareness bolted on, the center of gravity doesn’t shift. Every design decision, every default, every optimization still favors aggregate computation. Entity traversal becomes a second-class capability fighting for oxygen inside an architecture that wasn’t shaped for it.
This is the data infrastructure equivalent of adding a camera to a flip phone. The result technically takes photos, but the architecture was never designed around the camera.
The iPhone didn’t win by adding a camera to a phone. It won by designing around the camera and including a phone. Ontology-first infrastructure with metric governance plugged in is the iPhone architecture. A semantic layer with entity awareness bolted on is the flip phone with a camera.
Jessica Talisman made this point precisely in Metadata Weekly. The gap between metric definitions and formal ontologies may be too wide to bridge incrementally, since YAML configurations and ontology formats represent fundamentally different approaches to knowledge. You can’t incrementally extend your way from one paradigm into the other.
What “Ontology-First” Means in Practice
The agent designs I’ve seen actually ship in production share an inversion. Ontology first, then metric governance plugs in. Starting from entities and relationships and layering metric governance on top produces a distinctly different architecture than starting from metrics and trying to bolt on entity awareness later. The order of operations determines the center of gravity, and the center of gravity determines what works at scale.
The teams that understand this distinction will build agents that work. The rest will ship increasingly sophisticated demos.
Nobody Owns the Entity Model
The hardest part of this transition isn’t technical. It’s organizational.
Ask a data team, “Who owns metric definitions.” You usually get a clear answer. Analytics engineering. The dbt project. The semantic layer config. Ownership, workflow, and accountability are well established.
Now ask, “Who owns the entity model.” Who decided that a customer in Stripe, Salesforce, your support tool, and your product database are the same real-world thing. Who maintains the rules for how they connect.
In many orgs, you get a pause. Sometimes you get a shrug.
Where This Knowledge Actually Lives
The knowledge exists, but it lives in the heads of account managers, support reps, sales ops, and sometimes one engineer who has been there forever. They know that “Acme Corp” in Salesforce is the same as “Acme Corporation Ltd” in billing. They know which tags imply billing pain versus technical pain. They’ve rarely been asked to formalize any of it into infrastructure.
Nobody’s job description includes “maintain the entity model,” so nobody maintains it. No tool asks for this knowledge. No workflow captures it. No role is responsible for it. This is why ontology doesn’t get built. The organizational practice doesn’t exist yet, and the entity knowledge that agents need stays locked in institutional memory, inaccessible to every agent that needs it.
Data engineers built schemas. Analysts built dashboards. Nobody built the map. That’s the real gap.
What Ownership Would Need to Look Like
Semantic layers succeeded partly because they gave a role a crisp job. Define metrics. Maintain them in code. Review changes. Deploy. Ontology will only succeed when an equivalent exists. A role responsible for entity definitions. A workflow for maintaining cross-system relationships. An expectation that entity knowledge is infrastructure, not tribal memory.
Without that organizational commitment, even the best tooling ends up as shelfware. The technology is the easy part. Getting a team to treat entity resolution as a first-class engineering discipline is the hard part, and it’s the part that determines whether agents actually work.
The Two-Question Diagnostic
You can find out this week whether you have this problem. Two questions is all it takes.
The Test
Ask your agent this first.
“What was Q3 revenue?”
If your semantic layer is working, it answers correctly.
Now ask this.
“Email the customers who received refunds last week and also had a negative support experience. Personalize each message based on their history.”
If the agent breaks on the second question, it’s rarely because the team forgot a metric. The breakdown happens because they have metric meaning but lack the structure and control the workflow depends on.
What the Second Question Actually Requires
The first question needs metric definitions. What counts as revenue, which quarter, what currency. The semantic layer was built for this.
The second question needs different infrastructure entirely.
Entity resolution. Which customers are the same person or account across tools.
Cross-system relationship traversal. How refunds, tickets, and contacts connect across billing, support, and CRM.
Contextual definitions. What “negative support experience” means in your domain, which is often not a single metric.
Action. A write path to compose and send messages with permissions and auditability.
No semantic layer on the market was designed for this. The second question requires knowing how entities connect across systems, what terms mean in context, and how to navigate from one piece of the business to another. That’s ontology.
Give this test to your team. If the second question breaks, you know what’s missing, and you know it won’t be solved by a feature request. It requires a different foundation.
The Missing Practice
Semantic layers made a generation of teams great at defining numbers.
The teams that make agents work will treat entities and relationships the same way. They’ll assign an owner, build a change process, and demand production-grade control over the entity model. If they don’t, they’ll keep shipping impressive demos that break the moment the workflow crosses systems.
The gap is a missing practice, not a missing tool. Tooling that supports entity resolution and relationship modeling already exists. What’s missing is the organizational muscle around it. The semantic layer didn’t succeed because someone shipped a great product. It succeeded because it gave analytics engineers a clear job: define metrics, maintain them in code, review changes, deploy. All this with clear ownership and a clear workflow. An entire discipline formed around it. Ontology has none of that yet. Nobody owns it, no process governs it, and no expectation of rigor surrounds it. The tooling can be ready tomorrow. Until the discipline exists, entity knowledge stays trapped in the heads of the people who happen to understand how the business works, unavailable to every agent that needs it.
The question worth asking at your next data team standup isn’t “how do we make our semantic layer work for agents.” It’s “who in our organization understands how our business entities connect, and why has that knowledge never been formalized into infrastructure?”
That knowledge is the map. And agents can’t navigate without it.