
Beyond ETL: The Case for Context
ETL solved the movement problem. But movement doesn't address meaning.


ETL solved the movement problem a long time ago. We got good at extracting data from source systems, transforming it, and loading it into warehouses. But movement alone never addressed a harder problem. Meaning.
The business logic lives somewhere nobody can find it. Nobody owns the definition. And now the consumer of that data isn’t a dashboard but an autonomous agent making decisions at scale. Meaning doesn’t materialize from better prompts or smarter models. It requires dedicated infrastructure.
Ananth Packkildurai wrote the clearest articulation of this shift I’ve seen. His ECL framework, Extract, Contextualize, Link, names exactly what’s breaking and why.
I agree with the diagnosis. But I think the gap is narrower than it appears. The architectural patterns a Context Store requires, incremental replication, schema normalization, indexed search, tenant isolation, freshness SLAs, are patterns the data engineering community has been building for a decade. The Context Store isn’t waiting for invention. It’s waiting for the community to recognize that the infrastructure it already knows how to build has a new, urgent consumer.
The ECL Framework
Ananth’s ECL framework is one of the most useful reframings I’ve encountered in data engineering. For readers who haven’t read his essay, here’s the core idea.
Extraction remains necessary. Data still needs to move from source systems to where it can be used. But the center of gravity shifts from transformation to meaning. The hard work becomes giving data semantic clarity and connecting entities across systems.
What the Framework Gets Right
Three insights anchor the framework. First, transformation was always the brittle step, the place where business meaning was most likely to erode. Second, AI amplifies bad context at scale rather than fixing it. Third, the Context Store is the new engineering surface where meaning gets formalized and governed.
This is thought leadership from a respected voice in data engineering, and it resonates because the failure modes Ananth identifies show up again and again in the conversations I have with founders and builders.
Repeating Failure Modes
The same observations keep surfacing, and they all point to meaning as the bottleneck.
Transformation is where definitions disappear. A founder building a revenue ops copilot described a familiar problem. They had a dbt model that encoded “qualified lead,” but nobody could tell you why the logic looked the way it did, who signed off on it, or when it last changed. The agent inherited that invisible definition, and nobody felt responsible for it.
This is the accountability gap Ananth identifies in the “T” of ETL. Transformation logic was never really about data formatting, it was about encoding business meaning, and it was the step where meaning was most likely to get buried. When a data engineer hard-codes the definition of “active user” into SQL, that definition becomes invisible infrastructure: undocumented, unversioned, and disconnected from the people who own the business logic. The problem isn’t the code, it’s that meaning was never externalized from the code in the first place.
That accountability gap compounds once AI enters the picture. When an agent hits bad context, it doesn’t fail once. It fails the same way, every time, across every customer, until someone notices. AI-generated transformation code faithfully implements whatever definition it’s given, which means ambiguous or outdated definitions get amplified systematically instead of failing in isolated, catchable ways. One team told me they used an LLM to generate mapping logic for a SaaS connector, and it worked on their test tenant. Then it silently miscategorized records for a week in production after a custom field changed, because the contract governing inputs was ambiguous and nobody was validating the semantics.
These failures are pushing teams toward a new pattern. Several I’ve spoken with have independently built some version of a “context registry” or “glossary service” that sits next to their data. It’s versioned, queryable, and access controlled. The agent reads that first, then reads the underlying records.
They didn’t start by calling it a Context Store. They started because they were tired of context being trapped in SQL and prompt templates.
An Infrastructure Problem in an AI Costume
The AI layer in the Contextualize step matters. Inference, validation, human-in-the-loop labeling are real capabilities that move the needle. But they sit on top of infrastructure that is entirely non-magical. In practice, the same “agent” roadmap turns into building and operating a dependable data surface.
Here’s the mismatch teams keep running into.
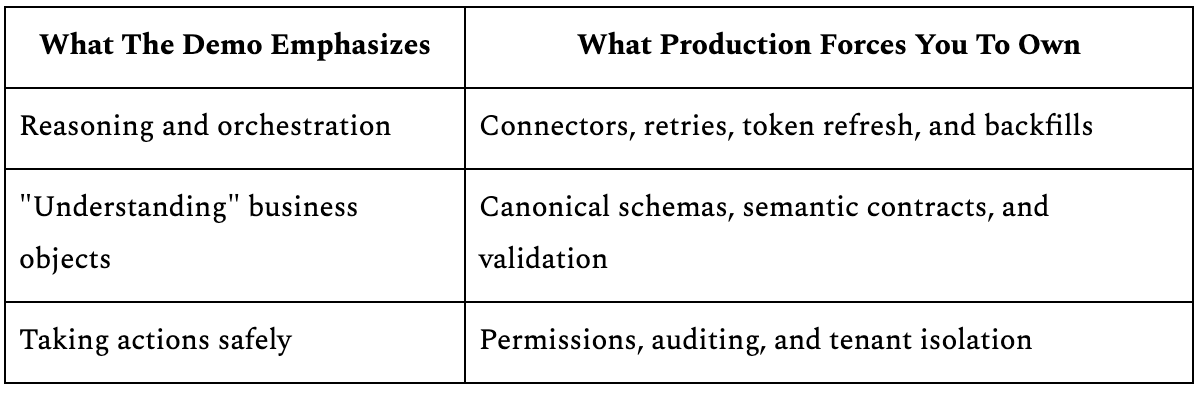
The Plumbing Behind the Contextualize Step
The Contextualize step turns into plumbing faster than anyone expects. The names change, but the work stays the same.
Replication jobs that populate the Context Store with searchable subsets of source data on a schedule.
Normalization logic that maps vendor-specific schemas into searchable structures.
Indexing layers that make cross-record queries fast.
Multi-tenant isolation that keeps one organization’s context separate from another’s.
In conversations with teams building agents, you hear the same realization in different words. “We thought we were building an agent, and then we realized we were building a data pipeline.”
The data engineering community has been here before. The modern data stack didn’t invent new computer science, it took existing database primitives and aimed them at a new problem. The same thing is happening now. The Contextualize step doesn’t ask the community to learn a new discipline, it asks them to aim an existing one at a new surface.
The tooling already exists. It’s just aimed at the wrong consumer.
The Unsolved Governance Layer
The gap teams feel today is practical, not mystical. Nobody has settled who owns the definitions, how conflicts between teams get adjudicated, or how “discovered” context inferred from messy SaaS exports earns the right to become official.
Agent builders are improvising these patterns right now, putting definitions in Notion, in YAML files next to prompts, in internal services. None of those are stable answers yet.
But the underlying infrastructure patterns a Context Store needs are patterns this community has been building for a decade: incremental replication, schema normalization, indexed search, tenant isolation, freshness SLAs. The building blocks already exist, though governance templates don’t, and that’s where the real work remains.
The Context Store as Materialized View
A Context Store is a materialization decision, not a storage decision. Making the analogy concrete clarifies why.
The Materialized View Precedent
Analysts needed aggregated data, but computing aggregations from raw tables at query time was too slow, too expensive, and too fragile at scale. So the industry pre-computed the answers and stored them in a structure designed for the consumer. Know your consumer, pre-compute what they need, serve it fast.
Semantic layers applied the same logic to business definitions. Cube, dbt metrics, Looker’s LookML each externalized what “revenue” meant so it didn’t get re-derived in every dashboard query.
A Context Store is a dedicated, versioned, queryable store of semantic definitions, entity classifications, and relationship maps. That sounds novel, but the underlying pattern is familiar. The Context Store extends the materialization principle to agents. Pre-replicate the operational data they need, normalize it into a searchable structure, and index it for fast retrieval. Agents query meaning instead of raw API payloads, not because the pattern is new, but because the consumer is.
The Failure of Query-Time Inference
The alternative is query-time inference, where the agent paginates through a vendor API at runtime, deals with rate limits and inconsistent schemas, burns context-window tokens on raw payloads, and tries to figure out what “deal stage” means for this particular CRM, which works in demos but not in production.
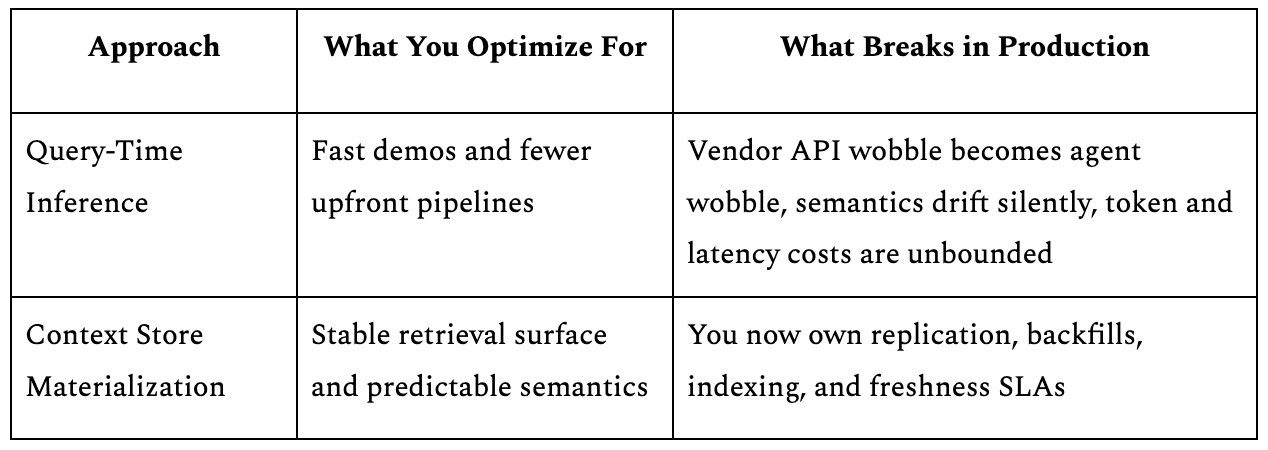
One support copilot team learned this firsthand. Their early prototype did everything at read time. It felt elegant until the first on-call rotation, when every vendor API wobble became an agent outage. They ended up backfilling a local store and treating it like a product, with freshness guarantees and rollbacks.
The early data warehouse debate asked the same question: materialize aggregations or compute them at read time? Materialization won because of latency, cost, and reliability at scale, and the economics haven’t changed, only the consumer has.
The Accountability Boundary
One of the most practical ideas from Ananth’s essay is the accountability boundary, and teams I talk to have converged on it independently.
Early Binding vs. Late Binding
The concept hinges on two modes. Early binding means prescribing context at the source, where you can hold the data producer to a contract. A team within your company owns a service, so you can enforce schema guarantees, version changes, and semantic contracts. Late binding means discovering context after the fact through the Contextualize pipeline, because you can’t hold the producer accountable. A third-party SaaS tool changes its API schema without notice, and you have no influence.
That distinction matters enormously for agentic workloads, because the majority of operational data agents need to sit on the far side of that boundary.
The Data Agents Actually Touch
Think about the data agents reach for day to day.
For most organizations, that means CRM records from Salesforce, tickets from Jira or Zendesk, conversations from Slack, code from GitHub, and product usage from tools like Amplitude or Mixpanel.
The majority of this operational data lives in third-party SaaS systems where you have zero ability to enforce a contract on the vendor’s schema or semantics.
The Contextualize step and Context Store aren’t optional add-ons for edge cases. They’re the primary path for the data that matters most to agents. Any agentic data infrastructure strategy that assumes early binding is sufficient is ignoring where agents actually need to operate. Data contracts are necessary, but for the data that matters most, replication-powered discovery is where the volume lives.
Context Erosion and the Relay
The Git Analogy
Ananth’s most clarifying moment is his git analogy, and it deserves unpacking. A file can be modified heavily across dozens of commits, refactored, renamed, moved, rewritten, but the context of how it got there is never lost, because it lives in the commit history, not in the file itself. The Gold layer is the latest commit. The lineage graph is the git log. The Context Store is the understanding you build by reading that log systematically.
How Context Erodes
This reframe makes visible what I’d call context erosion. Context doesn’t travel through a data pipeline. It erodes through it. Every transformation layer in the Medallion architecture, Bronze to Silver to Gold, makes editorial decisions that collapse semantic richness captured at the source. A column gets renamed, a category gets mapped, a join introduces ambiguity about which record took precedence. Each step loses meaning that was present at extraction.
Context needs to travel alongside the pipeline as metadata, lineage, and provenance. The Context Store exists to counteract this erosion by maintaining meaning as a separate, parallel artifact. Externalized, versioned, and queryable rather than embedded in transformation code or implicit in column names.
The Data Engineer as Context Architect
The new surface is the Context Store. What gets replicated, how it’s indexed, what freshness guarantees it carries, who owns it, and how agents access it. These are the architectural questions now. This is trade-off work applied to meaning instead of movement and it will define the discipline for the next decade.
The organizational patterns for governing who owns the Context Store don’t have established templates yet, and we’re figuring that out in real time. But the underlying infrastructure is not a mystery. Incremental replication, schema normalization, multi-tenant isolation, freshness guarantees: this community has been building these patterns for a decade. The hard parts aren’t the AI parts. They’re the data engineering parts, and data engineers already know how to solve them.
The Context Store isn’t waiting for invention. It’s waiting for the community to recognize that the infrastructure it already knows how to build has a new, urgent consumer. The model race is visible and thrilling. But the decisive work is happening one layer down, in the plumbing that gives agents something worth reasoning about. That’s where the next era of data engineering will be won.